Apache Spark – A Unified Analytics Engine
One engine to rule them all: sql , batch, streaming, ML, and more.
Apache Spark was built with a clear mission: replace the cluttered Hadoop ecosystem with a single, unified engine that handles all kinds of big data workloads—from batch jobs to real-time processing, machine learning, and graph computation.
Core Components of Apache Spark
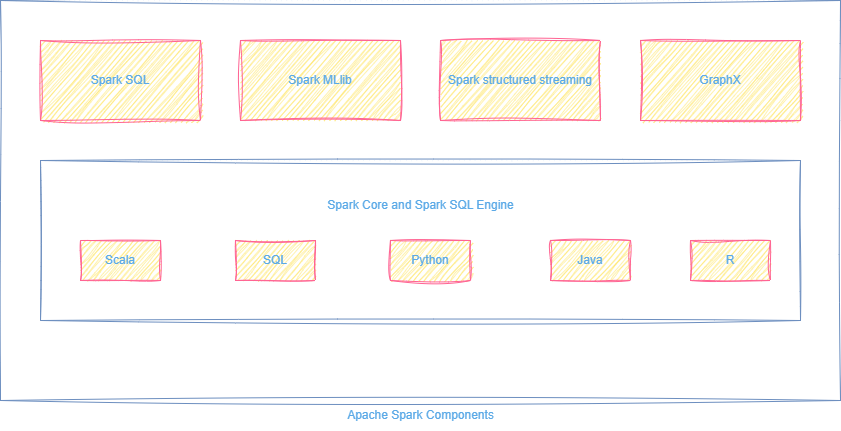
Apache Spark is structured like a stack of specialized libraries that sit on top of a powerful core execution engine:
All these components use the same execution engine, making Spark powerful and efficient across all workloads.
How Spark Handles Big Data Efficiently
💡 Did You Know?
• Spark can run on top of Hadoop, standalone, on Kubernetes, or in the cloud—it's extremely flexible.
• Structured Streaming uses the same Spark SQL engine, so developers don’t need to learn a new API.
• GraphX treats graphs as RDDs, making it easy to switch between graph algorithms and standard Spark transformations.
Components of Apache Spark
See the visual architecture below:
💡 Fun Facts
• You can use SQL, Python, or Scala to process streaming data in real time—within the same Spark job!
📚 Study Notes
• Spark unifies the big data ecosystem into a single engine with specialized components:
o SQL (Spark SQL)
o ML ( MLlib )
o Streaming (Structured Streaming)
o Graph ( GraphX )
• Spark’s in-memory architecture and DAG execution model help it outperform legacy systems like MapReduce.
• RDDs, DataFrames , and Datasets are the key data abstractions Spark uses for all tasks.