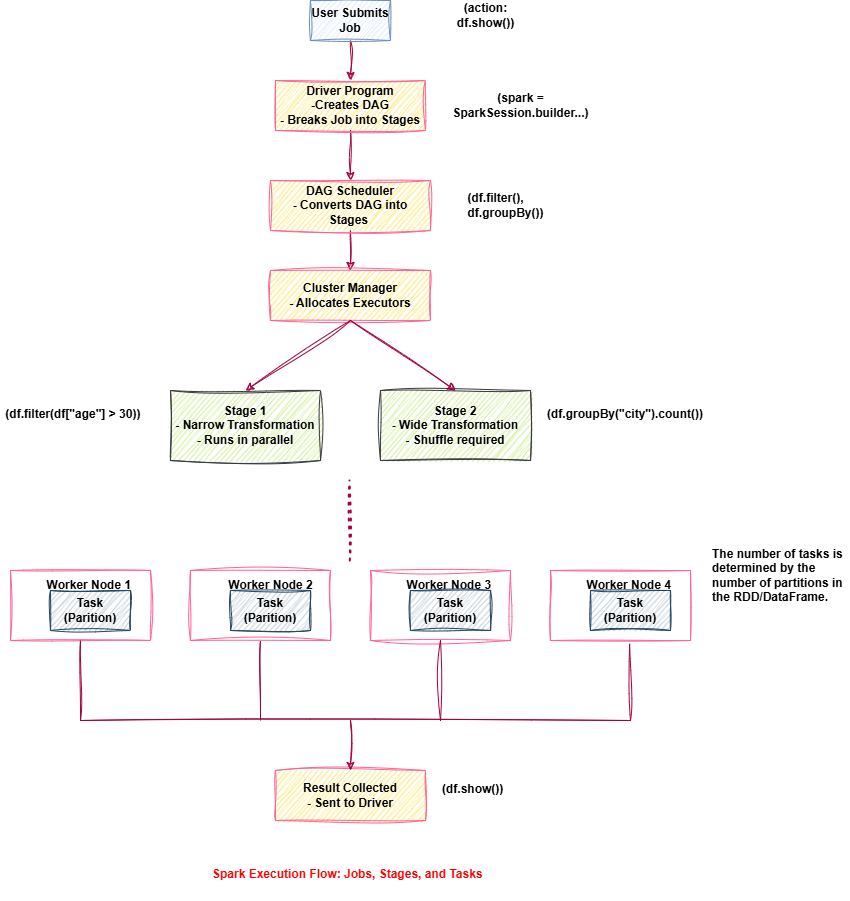
Example: Spark Job Execution
Understanding Spark becomes much easier when you see it in action. Let’s break down a simple PySpark example and track how it becomes a Spark Job, broken into Stages and Tasks.
Example: Code That Triggers a Spark Job
Breakdown of Execution Flow
|
Step |
What Happens |
Execution Type |
|---|---|---|
|
read.csv( ) |
Spark loads schema lazily |
No execution yet |
|
filter( ) |
Transformation is recorded in DAG |
Narrow transformation |
|
groupBy ( ).count () |
Adds a wide transformation |
Shuffle required |
|
show( ) |
Triggers a Job |
Action: execution begins |
|
Component |
Definition |
Example |
|---|---|---|
|
Job |
A high-level execution triggered when an action (like show( ), collect( ), count( )) is called. |
df.show () creates a job |
|
Stage |
A set of tasks that can be executed in parallel. A job is divided into multiple stages based on transformations. |
filter( ) (Stage 1) → groupBy ( ) (Stage 2) |
|
Task |
The smallest unit of execution, where each task processes a data partition. |
task1 processes Partition 1, task2 processes Partition 2 |
How Spark Sees This Code
|
Execution Step |
Type |
Example |
|---|---|---|
|
filter( df [“age”] > 30) |
Narrow Transformation |
Stays within Stage 1 |
|
groupBy ("city" ).count () |
Wide Transformation (Shuffle required) |
New Stage 2 is created |
|
show( ) |
Action (Triggers Job) |
Spark creates a Job |
|
Tasks |
Executed on Worker Nodes |
Each task processes a data partition |
💡 Did You Know?
• The number of Tasks created equals the number of data partitions. You can control partitions using .repartition () or .coalesce ().
• Wide transformations (like groupBy ) require shuffles—these are expensive and should be minimized when possible.
📚 Study Notes
• Driver → DAG → Stages → Tasks → Executors
• Transformations ( like filter ( ), groupBy ( )) are lazy and only recorded .
• Actions ( like show ( ), collect ( )) trigger the actual job execution .
• Spark splits the job into Stages depending on shuffle boundaries .
• Executors run Tasks in parallel on partitions across Worker Nodes .
• You can track this entire process visually in the Spark Web UI .