How Spark Differs from Traditional Data Processing
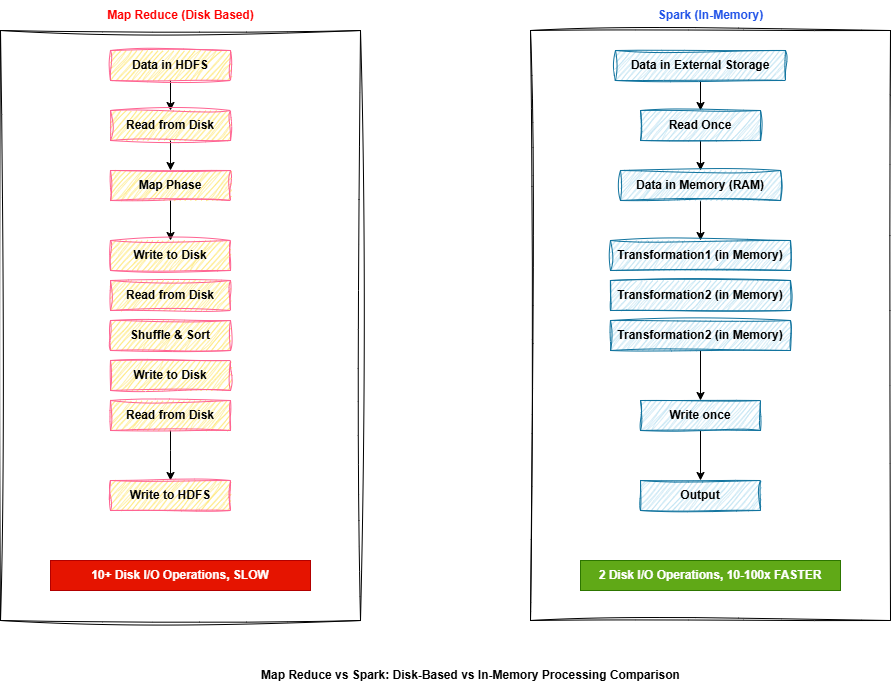
In a typical analytics workflow with 10 transformation steps, traditional systems might write to disk 10 times. Spark keeps everything in RAM and only writes when necessary. This is why Spark is dramatically faster.
Traditional Approach (Disk-Based)
Read Data → Process ( write to disk ) → Process ( write to disk ) → Process → Output
↓ ↓ ↓
Every step writes to disk = many I / O operations = SLOW
Spark Approach (In-Memory)
Read Data → Process ( in memory ) → Process ( in memory ) → Process → Output
↓
All intermediate results stay in memory = fewer I / O operations = FAST
MapReduce vs Spark Processing Flow:
Spark vs Traditional Single-Machine Tools :
|
Aspect |
Traditional Python/SQL |
Apache Spark |
|---|---|---|
|
Data Size Limit |
Fits in your computer's RAM (16-256 GB typically) |
Scales to petabytes across clusters |
|
Processing Speed |
Fast for small datasets; slows dramatically as data grows |
Maintains speed by adding machines |
|
Languages |
Limited to Python, R, SQL separately |
Python, Scala, Java, SQL, R unified |
|
Real-Time Processing |
Not designed for streaming data |
Built-in streaming capabilities |
|
Machine Learning |
Use libraries like scikit-learn; limited to single machine |
Built-in MLlib ; scales to clusters |
|
Fault Tolerance |
Crashes lose all progress |
Automatic recovery from node failures |
Limitations of Traditional Databases :
Relational Databases (MySQL, Oracle, PostgreSQL)
Traditional SQL databases excelled at structured, transactional data—perfect for banking systems, e-commerce, and business operations. But they hit a wall with big data:
In Summary: Traditional databases couldn't handle the volume, variety, or velocity of modern big data.