Spark – Jobs, Stages, and Tasks
Apache Spark processes data in layers of execution—when you run an action like .show () or .count (), it’s not just one operation.
Spark breaks it down into Jobs, then into Stages, and finally into many Tasks that run in parallel across a cluster.
Let’s walk through that process:
User Submits a Spark Action
When you run an action like .collect () , .show (), or .write (), Spark starts execution.
These actions trigger a Job, while earlier transformations (e.g., .filter () , .map ()) are just lazy steps stored in memory.
Driver Converts Job into a DAG
The Driver analyzes the chain of transformations.
Spark builds a Directed Acyclic Graph (DAG) to understand how to compute the result.
The DAG is split into Stages based on transformation types.
Stages and Tasks Are Created
A Stage is a collection of tasks that can run in parallel.
Narrow transformations ( like .map () , .filter ()) stay in the same stage.
Wide transformations ( like .groupBy () , .join ()) need data shuffles, creating new stages.
Cluster Manager Allocates Executors
The Cluster Manager assigns worker nodes (Executors) to handle the job.
Executors receive Tasks, one per data partition.
Executors Run Tasks and Return Results
Each Task runs independently on a data partition.
Results are either collected by the Driver (.collect ()) or written to storage (.write ()).
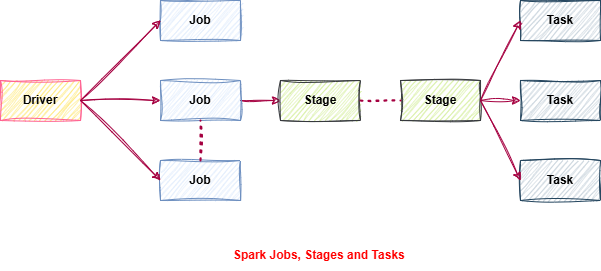
Jobs → Stages → Tasks
💡 Did You Know?
• Narrow vs Wide Transformations is how Spark decides how to split stages:
• Narrow → No shuffle → Same stage
• Wide → Shuffle → New stage
• Each Task is mapped to a data partition, which is why tuning partitioning is key for performance.
📚 Study Notes
• Action (e.g., .count ()) → triggers a Job
• Job → broken into Stages
• Stag es → broken into Tasks
• Executors run tasks and return results to the Driver
• Use Spark UI to inspect DAGs, Stage durations, and Task breakdowns