Spark vs Hadoop MapReduce
Apache Spark and Hadoop MapReduce are both distributed computing frameworks, but they represent different generations of big data processing technology—Spark uses in-memory processing while MapReduce relies on disk I/O, making Spark dramatically faster for most modern workloads but MapReduce still valuable in specific cost-constrained scenarios.
Understanding the differences isn't just academic—your choice between them directly impacts processing time, development effort, and operational costs. Let's break down how they compare.
Quick Comparison: What's Different?
|
Aspect |
Hadoop MapReduce |
Apache Spark |
|---|---|---|
|
Data Storage |
Disk-based (HDFS) |
In-memory (RAM) + Disk fallback |
|
Processing Speed |
Slower; many disk writes |
10-100x faster; minimal disk I/O |
|
Data Movement |
Data moves to compute |
Data moved once; stays in memory |
|
Iterative Workloads |
Very slow; re-reads data each iteration |
Fast; data in memory across iterations |
|
Real-Time Processing |
Not designed for it |
Built-in streaming capabilities |
|
API Simplicity |
Low-level Map/Reduce model |
High-level DataFrames, SQL, Python |
|
ML Performance |
Inefficient for ML |
Optimized for iterative ML algorithms |
|
Learning Curve |
Steep; requires Java expertise |
Gentler; Python, Scala, SQL available |
|
Unified Workloads |
Requires separate tools for ML, streaming |
All in one framework |
|
Fault Tolerance |
RDD lineage recomputation |
RDD lineage recomputation |
|
Resource Overhead |
Light; minimal memory per task |
Higher memory requirements |
|
When to Use |
Large jobs on limited hardware; cost-first |
Most modern use cases; speed-first |
Architecture: How They Process Data Differently
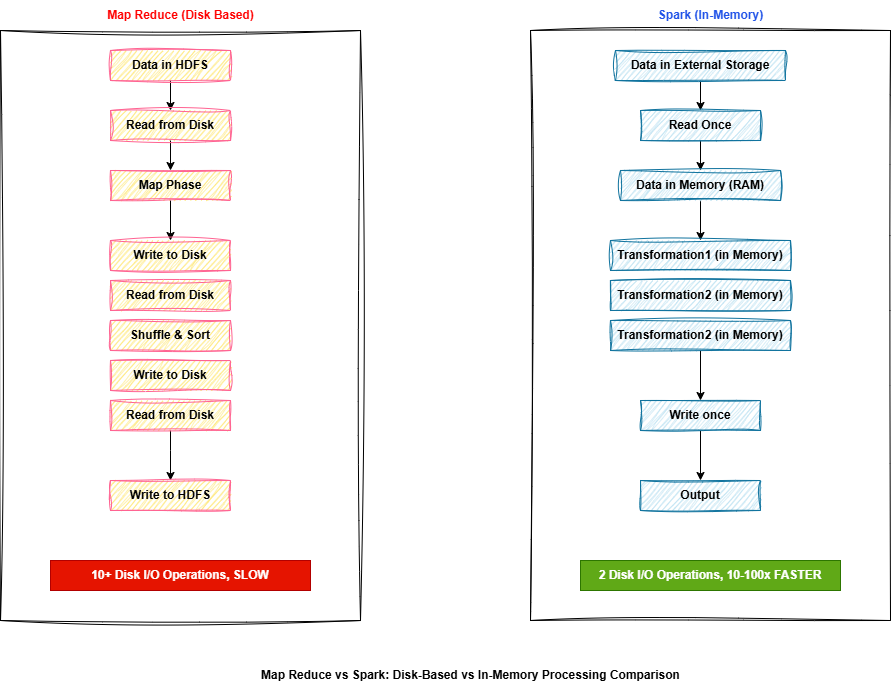
MapReduce Architecture: The Disk-Bound Approach
MAPREDUCE EXECUTION FLOW
Data in HDFS
↓ (Read from disk)
Map Phase: Process data → Output to DISK
↓ (Read from disk)
Shuffle & Sort: Reorganize → Write to DISK
↓ (Read from disk)
Reduce Phase: Aggregate → Write to HDFS
KEY INSIGHT: Every phase reads AND writes to disk
10-step job = 20+ disk I/O operations
How it works:
The Cost: Every step means disk I/O. For a simple 2-step job, data is written to disk 2-3 times. For a 10-step job, it's written 10+ times. Disk I/O is one of the slowest operations in computing.
Spark Architecture: The In-Memory Approach
SPARK EXECUTION FLOW
Data in External Storage (HDFS, S3, etc.)
↓ (Read once)
Load into Memory (RAM across cluster)
↓
Transformation 1 (in memory)
↓
Transformation 2 (in memory)
↓
Transformation 3 (in memory)
↓(Write once)
Write Results
KEY INSIGHT: Data stays in memory between steps
10-step job = 2 disk I/O operations
The Efficiency: Data read from external storage once and loaded into memory. All transformations happen in RAM. Intermediate results stay in memory. Only final output written to disk.
The Impact: For 10 transformations:
Performance Comparison:
Let's look at actual benchmark results for common operations on a 1TB dataset:
|
Operation |
MapReduce |
Spark |
Speedup |
Why Spark Wins |
|---|---|---|---|---|
|
Count distinct values |
120 seconds |
8 seconds |
15x faster |
In-memory scan vs disk reads |
|
Join two datasets |
250 seconds |
25 seconds |
10x faster |
No shuffle to disk |
|
Sort dataset |
300 seconds |
45 seconds |
6.7x faster |
Memory-based sorting |
|
Iterative ML (10 iterations) |
600 seconds |
35 seconds |
17x faster |
Data stays in RAM |
|
Simple filter & aggregate |
90 seconds |
5 seconds |
18x faster |
Minimal I/O |
|
Word count (classic benchmark) |
70 seconds |
4 seconds |
17.5x faster |
Pure memory processing |
Key Pattern: The larger the job and the more iterations, the bigger Spark's advantage.
Execution Model Differences :
MapReduce: Task-Focused
MapReduce breaks work into:
Your job is restricted to this Map-Reduce pattern. Want to do something more complex? You need to chain MapReduce jobs together, which means writing intermediate results to disk between jobs.
Example: Filter → Group → Join
MapReduce Approach:
├─ Job 1: Read data, filter → Output to disk
├─ Job 2: Read filtered data, group → Output to disk
└─ Job 3: Read grouped data, join → Output to disk
Cost: 3 job submissions × 3 disk I/O cycles = 9 disk operations
Spark: Transformation-Based with Lazy Evaluation
Spark gives you flexibility:
Spark builds a logical plan of all transformations you want to do, then optimizes it automatically using Catalyst Optimizer.
Same example in Spark:
result = (spark.read.parquet("data")
.filter(condition)
.groupBy("key")
.join(other_df)
.write.parquet("output"))
All transformations are lazy (not executed immediately). Spark analyzes the entire chain, applies optimizations, and executes efficiently . No intermediate disk writes.
Development Productivity Comparison:
|
Metric |
MapReduce |
Spark |
|---|---|---|
|
Lines of code |
60+ |
45780 |
|
Time to write |
2-3 hours |
5-10 minutes |
|
Testing difficulty |
Hard (distributed) |
Easy (local mode) |
|
Who can write it |
Java developers only |
Analysts, engineers, data scientists |
Fault Tolerance: Both Have It, Implemented Differently
MapReduce Fault Tolerance
If a task fails:
The mechanism is straightforward—recompute the lost task.
Spark Fault Tolerance
Spark uses RDD (Resilient Distributed Dataset) lineage:
Both frameworks recover from failures, but Spark's approach is more efficient—you only recompute what you actually lost, not the entire task.
Real-World Decision Matrix
|
Scenario |
Choose |
Why |
|---|---|---|
|
New analytics platform for startup |
Spark |
Speed, productivity, modern |
|
Existing Hadoop cluster running batch ETL |
Spark on YARN |
Leverage existing infrastructure + modern processing |
|
Real-time fraud detection for bank |
Spark |
Streaming capability essential |
|
Legacy system with strict cost limits |
MapReduce |
Works on older, cheaper hardware |
|
ML pipeline for recommendation engine |
Spark |
Iterative algorithms much faster |
|
Daily batch reporting on old system |
MapReduce |
Minimal change to legacy system |
|
Ad-tech company processing RTB data |
Spark |
High volume + real-time + ML needs |
|
Government data center with fixed budget |
MapReduce |
Cost priority over speed |
The Industry Consensus
By 2020+, the consensus is clear: For new projects, Spark is the default choice.
Organizations that still use MapReduce are usually maintaining legacy systems or dealing with extreme hardware constraints. Even Hadoop's creators acknowledged this—the latest Hadoop distributions come with Spark pre-installed and recommended over native MapReduce for most use cases.
💡 Did You Know?
📚 Study Notes