Data Engineering Roadmap
Data engineering has evolved from a niche technical specialty into one of the most in-demand and strategically critical roles in technology.
In 2025-2026, the field is characterized by fundamental architectural shifts—including the rise of lakehouse systems, AI-powered automation, real-time streaming, and federated governance models—alongside a clear maturation in career pathways, compensation, and specialization opportunities.
Organizations are experiencing annual growth of 15-20% in data engineering roles, driven by exponential data volumes, AI adoption requirements, and the recognition that data infrastructure is a competitive differentiator.
This roadmap provides a structured framework for professionals at any stage—from beginners to senior architects—to navigate skill development, technology choices, and career progression with confidence and strategic clarity.

Industry Context & Market Dynamics
Market Growth & Demand
Data engineering roles are experiencing unprecedented demand, with positions growing at 15-20% annually, significantly outpacing many other technical specialties. This growth reflects a fundamental organizational realization: data infrastructure is no longer supporting infrastructure but rather core intellectual property. Companies across finance, healthcare, retail, manufacturing, and entertainment recognize that their competitive advantage depends on reliable, scalable data systems that can power analytics, machine learning, and real-time decision-making.
The field has transitioned from a role primarily involving extract-transform-load (ETL) scripting to a sophisticated discipline encompassing systems architecture, cost optimization, data governance, and organizational strategy. This transition is evident in job descriptions, which increasingly emphasize "designing scalable data architectures" and "translating business requirements into technical solutions" rather than narrow technical expertise in specific tools.
Compensation & Career Opportunity
The 2025-2026 salary landscape reflects this strategic importance. Entry-level data engineers earn $80,000-$110,000, while mid-level engineers (3-5 years) command $118,000-$150,000 nationally in the US, with significant regional premiums in tech hubs. San Francisco and San Jose offer mid-level salaries of $148,000-$186,000, with senior roles reaching $183,000-$233,000.
Importantly, salary trends show a shift toward higher-paying positions. In 2024, the most common salary range was $80,000-$100,000, but by 2025, positions offering $160,000-$200,000 have become the third most common category, indicating organizations are willing to invest significantly in experienced talent.
Career Progression Framework
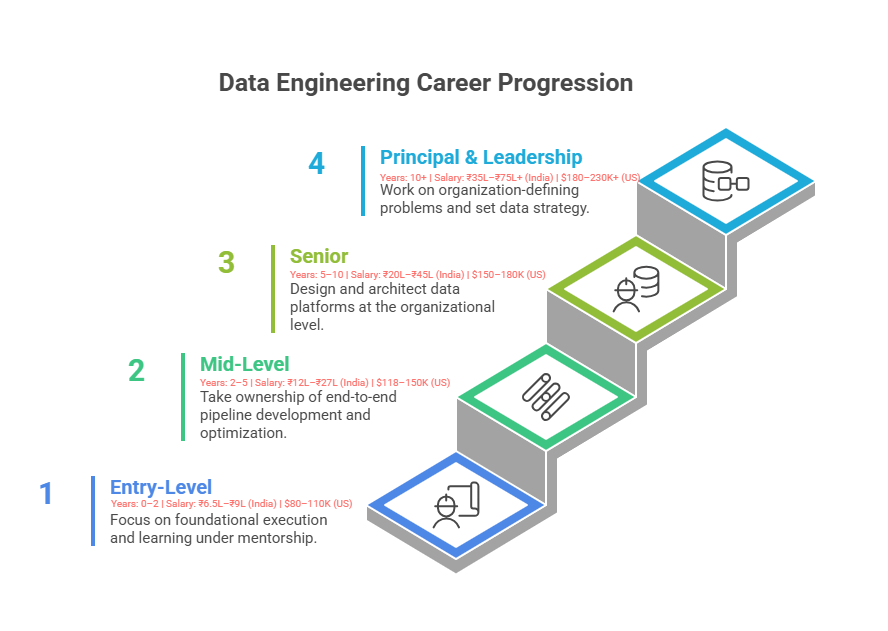
Entry-Level (0-2 Years)
Entry-level data engineers focus on foundational execution and learning under experienced mentorship. Responsibilities include maintaining existing pipelines, debugging issues, understanding data sources, and learning organizational data practices. The typical career title is Junior Data Engineer or Data Engineer I. During this phase, professionals build mental models for how data flows through systems and develop fluency with core technologies.
Success at this level requires meticulous attention to operational detail, ability to learn from debugging failures, and genuine curiosity about why systems work the way they do. Most entry-level engineers spend 50-70% of their time troubleshooting, learning, and understanding existing systems, with the remainder on minor feature additions or documentation.
Mid-Level (2-5 Years)
Mid-level engineers take ownership of end-to-end pipeline development, from requirements gathering through deployment and monitoring. They begin optimizing for performance and scalability, collaborate with analytics and product teams, and start mentoring junior engineers informally. The typical title is Senior Data Engineer or Data Engineer III.
This level represents the inflection point where engineers shift from "executing assigned tasks" to "owning outcomes." Mid-level engineers propose architectural solutions, push back on unrealistic requirements, and make technology trade-off decisions. They are expected to reduce their own support burden through automation and documentation, freeing capacity for more strategic work.
Senior (5-10 Years)
Senior data engineers design and architect data platforms at the organizational level. They lead the design of new systems, define data governance standards, establish best practices, mentor and hire junior engineers, and guide company-wide data initiatives. Titles include Senior Data Engineer, Staff Data Engineer, or Data Architect (depending on organizational structure). Some organizations create specialist roles like Cloud Solutions Architect or Data Infrastructure Lead.
Senior engineers spend significant time in architecture discussions, strategy sessions, and cross-functional alignment meetings. They are expected to anticipate future requirements, prevent architectural debt, and think at the system and organizational level rather than the project level.
Principal & Leadership (10+ Years)
Principal engineers and data leaders work on organization-defining problems: designing multi-year architecture transformations, setting data strategy for the entire company, building and scaling data teams, and ensuring data becomes a competitive advantage. These roles often have titles like Principal Data Engineer, Director of Data Engineering, VP of Data, or Chief Data Officer.
Foundational Skills Development
Phase 1: SQL & Relational Databases (3-4 Months)
SQL is non-negotiable in data engineering. Unlike data scientists who may use tools abstracting SQL away, data engineers must achieve deep fluency with relational query patterns. The learning progression follows this sequence:
Basic SQL (Weeks 1-2): Master SELECT statements, WHERE filtering, ORDER BY sorting, and JOIN fundamentals (INNER, LEFT, RIGHT). Work with simple single-table queries and basic multi-table joins.
Intermediate SQL (Weeks 3-6): Learn aggregations (COUNT, SUM, AVG, MAX, GROUP BY, HAVING), subqueries, and database design principles including normalization (1NF, 2NF, 3NF). Understand indexes, query performance implications, and execution plans.
Advanced SQL (Weeks 7-12): Master window functions (ROW_NUMBER, RANK, DENSE_RANK, LAG, LEAD, PARTITION BY), recursive CTEs, transactions, and stored procedures. Practice complex analytical queries that combine multiple advanced concepts.
Key performance indicator for this phase: Ability to write complex multi-table queries with window functions, explain execution plans, and understand schema design trade-offs.
Phase 2: Python Programming (3-4 Months)
Python is the primary scripting and automation language in data engineering. Unlike data science-focused Python, data engineering emphasizes automation, error handling, and operational reliability.
Fundamentals (Weeks 1-3): Variables, data types, control flow (if-else, loops), functions, and error handling (try-except). Understand Python's execution model, mutable vs. immutable objects, and scope.
Data Structures & Libraries (Weeks 4-8): Master lists, dictionaries, tuples, and sets. Understand when and why to use each. Learn Pandas for tabular data manipulation, NumPy for numerical operations. Practice data transformation workflows: reading files, filtering, grouping, aggregating, and writing results.
Scripting & Automation (Weeks 9-12): Write production-quality scripts with proper logging, configuration management, and error handling. Learn about virtual environments, dependencies, and reproducibility. Understand how to structure code for reuse and testing.
Key performance indicator: Ability to write robust, maintainable Python scripts for data extraction, transformation, and loading with appropriate error handling and logging.
Phase 3: Database & System Design (2-3 Months)
Understand how databases actually work under the hood: storage engines, indexing strategies, query optimization, and ACID properties. Study schema design patterns—star schemas, snowflake schemas, one-big-table models, and dimensional modeling. Understand when each approach is appropriate and learn about partitioning strategies, denormalization trade-offs, and incremental loading patterns.
Cloud Platforms & Modern Infrastructure
Cloud Platform Selection
In 2025, proficiency with at least one major cloud platform—AWS, GCP, or Azure—is mandatory. Each platform has distinct characteristics:
AWS (Most Popular) offers the broadest service portfolio including S3 (object storage), Redshift (data warehouse), Glue (ETL service), and Lambda (serverless compute).
Google Cloud Platform excels with BigQuery, a fully managed, serverless data warehouse with built-in ML capabilities and superior integration with AI/ML services via Vertex AI.
Azure provides seamless integration for enterprises with existing Microsoft ecosystems and provides competitive advantages in hybrid cloud scenarios.
Learning path: Start with cloud fundamentals (storage, compute, networking, IAM). Progress to managed data services (warehouse, lakes, analytics). Master Infrastructure as Code (Terraform) to define infrastructure through code rather than manual console clicking. Understand pricing models, cost optimization strategies, and when to use serverless vs. managed services.
Container Orchestration & IaC
Modern data engineering requires containerization and orchestration skills. Docker packages applications and dependencies into containers, ensuring reproducible deployments. Kubernetes orchestrates containers at scale, managing scheduling, scaling, networking, and storage.
Terraform enables Infrastructure as Code—defining desired infrastructure state in version-controlled configuration files rather than manual console operations. This ensures repeatability, enables disaster recovery, and allows infrastructure changes to follow software engineering workflows.
Data engineers should achieve competency in:
Modern Data Stack Architecture
Evolution from Traditional ETL to ELT & Lakehouses
The data stack has undergone fundamental transformation over the past five years. Traditional architectures separated concerns: data warehouses for analytics, data lakes for machine learning, and specialized systems for operational queries. This separation created redundancy, consistency challenges, and significant operational overhead.
The modern approach consolidates into lakehouse architectures, which combine the scalability and cost efficiency of data lakes with the reliability and governance capabilities of data warehouses. Lakehouses are characterized by:
Key Technology Categories
Data Quality & Observability
The Quality Paradigm Shift
The most significant operational shift in 2025 is the transition from reactive data quality management to proactive observability. Historically, data quality was a late-stage concern—validation at pipeline end, with failures triggering reactive debugging. This created "fail late" scenarios where bad data propagated downstream, corrupting analytics and model decisions.
Modern best practice inverts this: add data quality checks at every pipeline stage, fail fast on data anomalies, and maintain continuous observability of data health.
Data Quality vs. Data Observability
Effective data reliability requires both: data quality ensures data meets business requirements; data observability detects when data doesn't meet those requirements and enables rapid root cause analysis.
Implementation Framework
Data engineers should implement:
Emerging Specializations
DataOps Engineering
DataOps engineers focus on operationalizing data systems, applying DevOps principles to data infrastructure. Responsibilities include workflow automation, CI/CD for data code, infrastructure automation, cost optimization, and incident response.
Analytics Engineering
Analytics engineers bridge data engineering and business intelligence, transforming raw data into business-ready analytical assets using tools like dbt. They focus on data modeling, business logic implementation, and analytics platform development.
Data Mesh Architecture
Data Mesh represents a shift from centralized data teams to domain-oriented, federated data management. Its four principles are:
ML/AI Integration & Feature Stores
As machine learning becomes central to business operations, data engineers increasingly support ML infrastructure. Feature stores manage feature data for ML pipelines, providing offline and online storage. Vector databases (Pinecone, Milvus, Weaviate, Qdrant) store embeddings for semantic search and RAG applications.
The Data Engineer's Evolving Role
From Builder to Architect
The transition from mid to senior levels represents a shift from implementation focus to strategic thinking. Entry and mid-level engineers ask "How do I build this system?" Senior engineers ask "What problem are we solving?" and "What are the trade-offs between different approaches?" This strategic thinking increasingly differentiates valuable senior engineers.
Technical Leadership Without Management
Many organizations now offer "technical ladder" career progression, allowing senior engineers to advance in scope and compensation without managing teams.
Soft Skills Becoming Hard Requirements
Data engineering increasingly requires communication, business acumen, and stakeholder management. Engineers must translate between technical constraints and business requirements, influence teams without direct authority, and clearly articulate architectural decisions.
Learning Pathway & Practical Implementation
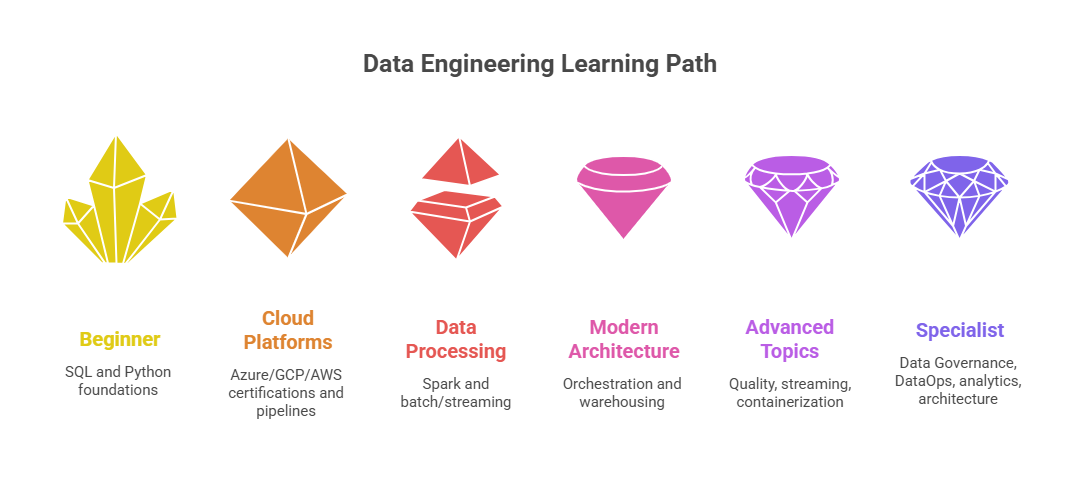
Phase 1: Foundations (3-4 Months)
Build strong SQL and Python foundations through structured study and practice. Hands-on project: Build a small data warehouse schema, load data via Python scripts, and query it using complex SQL.
Phase 2: Cloud Platforms (2-3 Months)
Choose one cloud provider ( Azure/AWS/GCP ). Complete official cloud certifications and build an end-to-end data pipeline on the cloud.
Phase 3: Data Processing (3-4 Months)
Master Apache Spark and batch vs. streaming processing paradigms. Hands-on project: Build a Spark job processing large datasets, optimize for performance, implement data quality checks.
Phase 4: Modern Architecture (3-4 Months)
Learn orchestration (Airflow), modern data warehousing (Snowflake or Databricks), and transformation tools (dbt). Hands-on project: Build production-grade multi-stage data pipeline.
Phase 5: Advanced Topics (2-3 Months)
Study data quality frameworks, real-time streaming, containerization, and Infrastructure as Code. Hands-on project: Implement data quality framework, add real-time streaming, containerize with Docker.
Phase 6: Specialization (Ongoing)
Pursue specialization aligned with career interests: DataOps, analytics engineering, data architecture, or ML engineering. Build public portfolio projects demonstrating expertise.
Portfolio Development Strategy
Create 3-5 public GitHub projects showing:
Each project should explain technical choices, trade-offs, and learnings.
Salary Expectations & Market Positioning
Data engineer compensation varies significantly by geography, experience level, and company. Below is a comprehensive breakdown across major markets.
United States (2025-2026)
India (2025-2026)
India has emerged as a major global data engineering hub with rapidly growing demand. The compensation structure reflects the country's position as both a talent provider for global companies and a growing domestic tech market:
Tier-1 cities (Bangalore, Mumbai, Pune, Hyderabad, Gurgaon) command 20-30% premiums over tier-2 cities. Multinational companies often pay 30-50% above local IT company rates. Bangalore leads with average ₹33.1 lakhs for experienced engineers, followed by Mumbai (₹8.8-9 lakhs entry) and Pune (₹9 lakhs).
Singapore (2025-2026)
Singapore remains Southeast Asia's premium tech hub:
Premium over regional average: 40-60% compared to other ASEAN nations.
Southeast Asia
Thailand
Vietnam
Philippines
East Asia
Japan
South Korea
Taiwan
South Asia (Beyond India)
Pakistan
Bangladesh
Sri Lanka
Key Insights on Asian Market Positioning
Talent Arbitrage: The significant wage differential between India/Southeast Asia and Western markets creates opportunities for global companies to build distributed teams while maintaining cost efficiency. However, this gap is narrowing as local tech ecosystems mature and competition increases.
Talent Quality: Major Indian cities (Bangalore, Hyderabad) and Singapore produce world-class data engineers competitive globally. Companies increasingly compete on challenging work and growth opportunities rather than just compensation.
Remote Work Impact: Remote-first global companies have disrupted traditional location-based pay scales. Engineers in tier-2 Indian cities now earn closer to tier-1 rates when working for US/European companies remotely.
Career Acceleration: The steep learning curve and rapid technology evolution in Asia create opportunities for accelerated career progression. An engineer advancing through 2-3 roles in India within 8-10 years might advance to senior or principal levels, significantly increasing lifetime earnings potential.
Geographic Arbitrage Strategy: Many successful Asian data engineers pursue this trajectory: start at local company (build fundamentals), transition to multinational offshore center (10-20% premium), then move to remote work for US/European companies (50-100% premium), or eventually relocate for maximum compensation.
Strategic Recommendations & Conclusion
For Aspiring Data Engineers
For Organizations Hiring Data Engineers
Future Trajectory
Trends likely to accelerate:
Data engineering has matured into a core strategic discipline. Success requires ongoing learning, deep technical execution, strategic thinking, and adaptability. This roadmap provides the foundational structure; individual choices on focus, specialization, and projects determine personal trajectory.