Data Science Roadmap
Data science has transformed from a specialized role into a critical strategic function within modern organizations. In 2025-2026, the field experiences unprecedented growth with a projected 36% job growth through 2033, significantly outpacing average occupational growth. The discipline is evolving rapidly, marked by the integration of generative AI, increased emphasis on responsible AI and governance, emergence of hybrid roles combining data science with MLOps and analytics engineering, and growing specialization across domains. Organizations globally are investing 25% or more of their AI budgets in data science talent and infrastructure, recognizing that data-driven decision-making is a competitive imperative.
This comprehensive roadmap provides structured guidance for professionals at all career stages—from aspiring data scientists to principal leaders—to navigate skill development, technology choices, career progression, and specialization opportunities across diverse global markets, with particular emphasis on Asia's rapidly growing data science ecosystem.
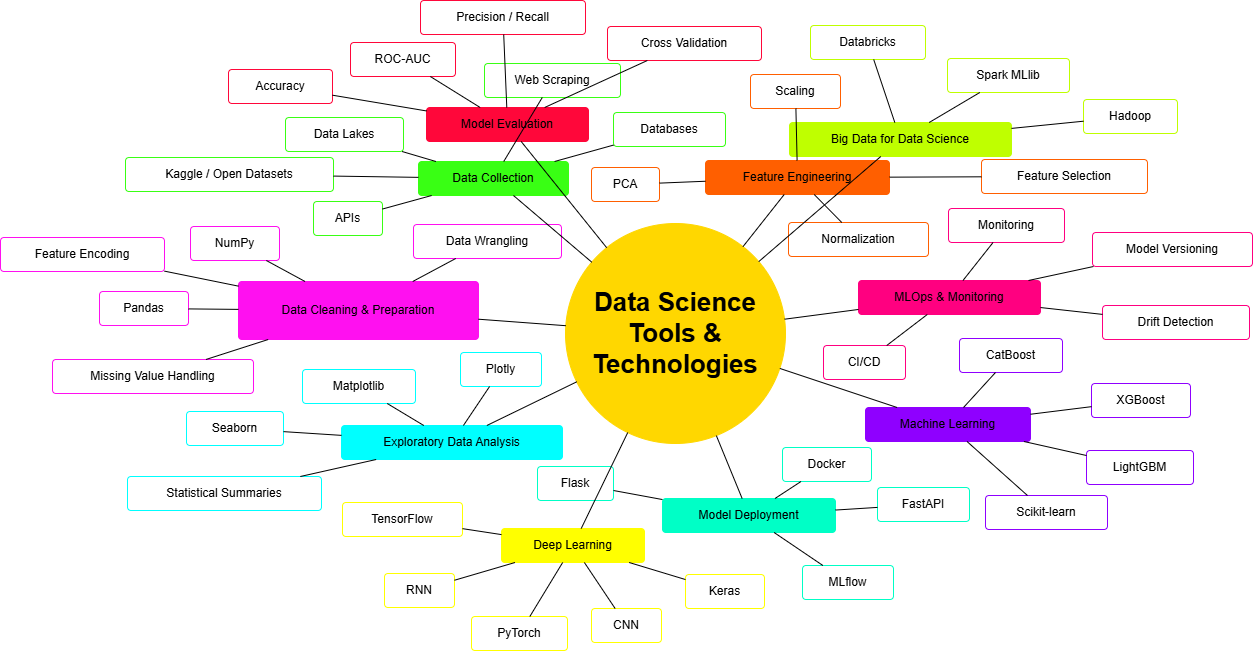
Industry Context & Market Dynamics
Global Market Growth & Demand
The data science job market is experiencing explosive growth. The U.S. Bureau of Labor Statistics projects 36% job growth for data scientists from 2023-2033, more than three times the average occupational growth rate. The global data science and analytics market reached $178.5 billion in 2025 and continues accelerating as organizations across finance, healthcare, manufacturing, retail, and technology sectors compete for data-driven competitive advantages.
Critically, demand extends beyond traditional "Data Scientist" titles. Organizations actively recruit data engineers (growing 49% over recent years), analytics engineers, MLOps specialists, NLP engineers, and AI product managers. This expansion reflects organizational recognition that data success requires specialized talent across the entire data ecosystem, not just predictive modeling.
Geographic Trends & Asia's Rise
Asia has emerged as a major global data science hub. India, Singapore, and other Southeast Asian countries produce competent data scientists at scale, with growing domestic demand for AI and ML capabilities. Investment in sovereign cloud platforms and regional data centers positions countries like Singapore, the UAE, and India as emerging global data hubs. Southeast Asia experienced record hiring demand in 2025, with AI and tech roles leading growth trajectories.
The convergence of three factors—massive talent pools, rising educational investment in AI/data science, and government initiatives supporting digital transformation—makes Asia increasingly attractive for both talent development and employment opportunities.
Career Progression Framework
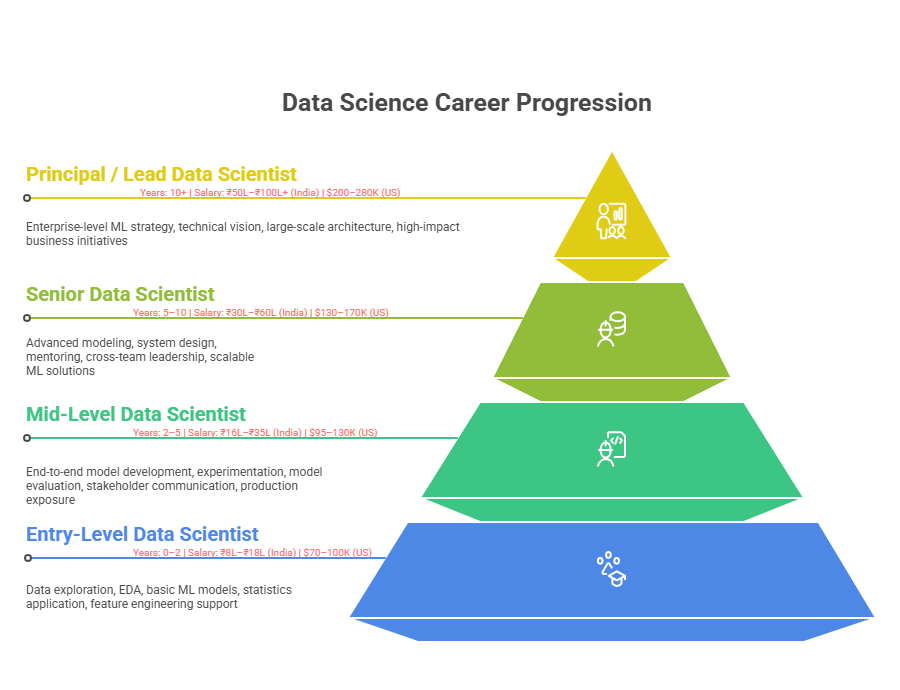
Entry-Level (0-2 Years)
Entry-level data scientists focus on foundational work under mentorship: data exploration and visualization, basic statistical analysis, simple machine learning model training on known datasets, and supporting senior data scientists with data preparation and feature engineering. Titles include Data Analyst, Junior Data Scientist, or Data Science Intern.
This phase emphasizes learning the end-to-end data science workflow, understanding business problems through data, and developing intuition about what constitutes good analysis. Most time (60-70%) involves data cleaning, exploratory data analysis, and working with structured datasets. Success requires curiosity, attention to detail, and ability to translate ambiguous business problems into analytical frameworks.
Mid-Level (2-5 Years)
Mid-level data scientists own projects from problem definition through model deployment. They design experiments, build production-grade models, present findings to business stakeholders, and begin specializing in particular domains or techniques. Titles include Data Scientist, Senior Data Scientist, or Data Scientist II/III.
This inflection point represents transition from "executing assigned tasks" to "driving outcomes." Mid-level practitioners propose analytical approaches, challenge assumptions, collaborate across functions, and improve model performance through systematic experimentation. They develop business acumen, understanding how analytics translate to business impact.
Senior (5-10 Years)
Senior data scientists architect end-to-end data science solutions at organizational scale, lead data science teams, define standards and best practices, mentor junior scientists, and translate complex business problems into technical solutions. Titles include Senior Data Scientist, Lead Data Scientist, Staff Data Scientist, or Data Science Manager.
Senior roles emphasize strategic thinking: anticipating future needs, preventing technical debt, and ensuring data science initiatives align with organizational strategy. These practitioners think in systems, understand organizational constraints, and navigate competing priorities to maximize impact.
Principal & Leadership (10+ Years)
Principal data scientists and data science leaders shape organizational data strategy, build and scale high-performing teams, drive cross-organizational initiatives, and ensure responsible AI practices. Titles include Principal Data Scientist, Director of Data Science, VP of Analytics, or Chief Data Officer.
These roles focus on organizational transformation, setting data science vision, building cultures valuing evidence-based decision-making, and ensuring data science creates sustainable competitive advantage.
Foundational Skills Development
Phase 1: Programming Fundamentals (3-4 Months)
Python (90% of data science roles) or R (statistics-heavy domains) form the foundation. Python dominates due to its extensive ecosystem (Pandas, NumPy, Scikit-Learn, TensorFlow) and versatility across domains.
Basic Python (Weeks 1-2): Variables, data types, control flow, functions, error handling. Write simple scripts solving algorithmic problems.
Data Manipulation (Weeks 3-6): Master Pandas for tabular data manipulation—loading, filtering, grouping, aggregating, joining, reshaping. Practice transforming raw data into analysis-ready formats.
Visualization (Weeks 7-9): Learn Matplotlib (publication-quality), Seaborn (statistical), Plotly (interactive). Practice communicating insights through compelling visualizations.
Libraries & Tools (Weeks 10-12): NumPy for numerical operations, Jupyter Notebooks for interactive development, IPython for enhanced shell. Develop productive workflows combining coding with documentation.
Key performance indicator: Ability to load datasets, perform exploratory analysis, create publication-quality visualizations, and prepare data for modeling.
Phase 2: SQL & Databases (2-3 Months)
SQL is critical because most organizational data lives in databases. Data scientists write SQL daily to extract, aggregate, and prepare data.
Fundamentals: SELECT, WHERE, ORDER BY, JOIN operations. Query single and multiple tables. Write window functions for time-series and ranking operations.
Advanced: Complex multi-table queries, aggregations with GROUP BY/HAVING, subqueries, CTEs (Common Table Expressions), query optimization, index usage.
Application: Extract features from raw data, create analysis tables, join data from multiple sources, handle null values and data quality issues at source.
Key performance indicator: Write complex SQL queries to extract analysis-ready datasets without requiring engineering support.
Phase 3: Statistics & Probability (2-3 Months)
Statistics is the theoretical foundation underlying all data science. Understanding distributions, hypothesis testing, p-values, and Bayesian thinking enables correct model interpretation.
Descriptive Statistics: Mean, median, mode, variance, standard deviation, correlation, covariance. Understand distributions—normal, binomial, Poisson.
Inferential Statistics: Hypothesis testing, confidence intervals, p-values, Type I/II errors. A/B testing methodology and interpretation.
Probability: Bayes' theorem, conditional probability, independence, distributions.
Application: Design and interpret experiments, validate model assumptions, translate statistical findings into business conclusions.
Key performance indicator: Correctly interpret statistical tests, design valid experiments, avoid common fallacies (p-hacking, multiple comparison problems).
Phase 4: Machine Learning Fundamentals (4-6 Months)
Shift from statistical analysis to predictive modeling. Understand how models learn from data and make predictions.
Supervised Learning: Regression (predicting continuous values), classification (predicting categories), evaluation metrics (RMSE, MSE, MAE, accuracy, precision, recall, F1, AUC).
Key Algorithms: Linear/logistic regression, decision trees, random forests, gradient boosting, support vector machines, k-nearest neighbors.
Unsupervised Learning: Clustering (k-means, hierarchical), dimensionality reduction (PCA), anomaly detection.
Model Development Process: Train-test split, cross-validation, hyperparameter tuning, feature engineering, handling class imbalance, regularization.
Scikit-Learn Mastery: Build, train, evaluate, and deploy models using Python's standard ML library.
Key performance indicator: Build production-grade models, properly evaluate them, avoid overfitting, communicate results to non-technical stakeholders.
Phase 5: Deep Learning & Neural Networks (3-4 Months)
Graduate to more complex architectures for image, text, and time-series problems.
Fundamentals: Neural network architecture, layers, activation functions, backpropagation, loss functions, optimization algorithms.
Frameworks: TensorFlow/Keras (Google) or PyTorch (Meta). Both are production-standard. Keras is more accessible for beginners.
Applications: CNNs for image recognition, RNNs/LSTMs for sequential data, Transformers for NLP.
Key performance indicator: Build neural networks for image/text/sequence problems, understand architectural choices, debug training issues.
Core Technology Stack
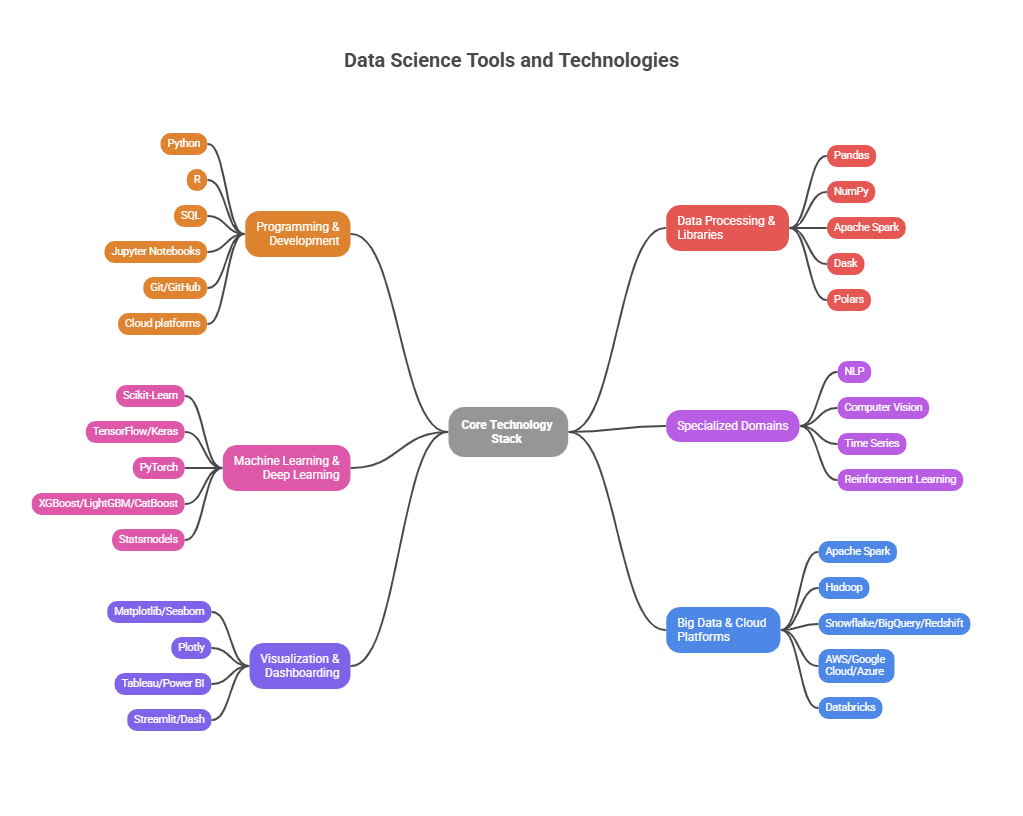
Programming & Development
Data Processing & Libraries
Machine Learning & Deep Learning
Specialized Domains
Visualization & Dashboarding
Big Data & Cloud Platforms
Emerging Specializations & Roles
Machine Learning Engineer
MLOps Engineer focuses on deploying and maintaining ML models in production. Responsibilities include model versioning, A/B testing infrastructure, retraining pipelines, monitoring for model drift, and ensuring reliability at scale. This role bridges data science and software engineering.
NLP Specialist / NLP Engineer
Natural Language Processing specialists work with text data: sentiment analysis, text classification, machine translation, question-answering, entity recognition. Expertise with Transformers, Large Language Models, and modern architectures (BERT, GPT, T5) is increasingly critical.
Computer Vision Engineer
Computer vision specialists work with image and video data: object detection, image classification, semantic segmentation, facial recognition. Deep expertise with CNNs, transfer learning, and deployment frameworks required.
Prompt Engineer & GenAI Specialist
A rapidly emerging role: crafting effective inputs to Large Language Models (ChatGPT, Claude, Gemini) to generate desired outputs. This role combines understanding of LLM capabilities with domain expertise and communication skills. Critical for organizations integrating generative AI into workflows.
Analytics Engineer
Analytics engineers bridge data engineering and data science, transforming raw data into business-ready analytical assets using SQL and dbt. They focus on data modeling, business logic implementation, and ensuring data consistency across analytics platforms.
AI Data Specialist
AI Data Specialists focus on preparing, labeling, and curating data for AI/ML systems. This role combines domain expertise, data annotation best practices, and quality assurance. Increasingly important as data quality directly impacts model performance.
MLOps Engineer
MLOps Engineers automate and operationalize ML workflows: continuous training, model deployment, monitoring, governance, and compliance. They apply DevOps principles to data science, ensuring models perform reliably in production.
Generative AI & LLM Integration (2025-2026 Imperative)
Prompt Engineering
Prompt engineering has emerged as a critical skill: crafting inputs to Large Language Models to generate desired outputs. Core techniques include:
Data scientists who master prompt engineering can accelerate workflows: generating code, creating documentation, exploring alternative analytical approaches, and automating routine tasks.
LLM Integration in Data Science Workflows
Organizations increasingly integrate LLMs into data pipelines:
AI-Augmented Data Science
The future role of data scientist is "AI-augmented"—using generative AI to enhance productivity while maintaining critical human judgment. Data scientists who leverage AI tools effectively (ChatGPT, GitHub Copilot, Claude) dramatically accelerate delivery while focusing on high-value analytical thinking.
Data Quality & Responsible AI
Data Quality
Modern data science emphasizes data quality: accuracy, completeness, consistency, timeliness. Poor data quality cascades through models, corrupting downstream decisions.
Implementation includes:
Responsible AI & Ethics
Increasingly, data scientists are responsible for ensuring models are fair, transparent, and ethical:
Organizations prioritize responsible AI; professionals demonstrating these competencies command premium compensation.
Learning Pathway & Implementation
Phase 1: Foundations (4-5 Months)
Master Python, SQL, and statistics through structured learning. Build 2-3 projects using public datasets (Kaggle). Create Jupyter notebooks explaining analysis at each stage. Time investment: 15-20 hours/week.
Phase 2: Machine Learning (3-4 Months)
Study classical ML algorithms deeply. Understand evaluation metrics, overfitting prevention, and hyperparameter tuning. Complete intermediate Kaggle competitions. Hands-on project: Build multiple models, compare performance, interpret results.
Phase 3: Deep Learning (2-3 Months)
Study neural network architectures, backpropagation, optimization. Build models for image classification and NLP tasks using public datasets. Hands-on project: Image classification using CNNs or text analysis using RNNs/Transformers.
Phase 4: Big Data & Cloud (2-3 Months)
Learn Spark for distributed computing and cloud platforms (AWS/GCP/Azure). Understand data pipelines at scale. Hands-on project: Build pipeline processing large dataset on cloud infrastructure.
Phase 5: Specialization & Advanced Topics (Ongoing)
Choose specialization: NLP, computer vision, MLOps, responsible AI, or domain-specific (healthcare, finance, e-commerce). Build advanced portfolio projects. Contribute to open-source projects in chosen area.
Portfolio Strategy
Build 4-5 public GitHub projects demonstrating:
Each project should document not just "what" was built but "why"—technical choices, alternatives considered, and lessons learned. This demonstrates judgment and reasoning.
Salary Expectations & Market Positioning
United States (2025-2026)
FAANG Total Compensation (salary + equity + bonus): $220K-$320K (mid-level), $350K-$500K (senior), $500K+ (principal).
India (2025-2026)
India has emerged as a major global data science hub with rapidly growing demand and rising compensation.
Key Cities by Compensation:
Multinational companies pay 30-50% above local IT company rates for equivalent experience. Remote work for US/European companies offers 50-100% premium over India-based roles.
Singapore (2025-2026)
Singapore commands premium compensation across Asia, positioning itself as Southeast Asia's financial and tech hub.
Morgan McKinley reports: Entry 5-10 years: SGD 50K-120K; Senior 10-15 years: SGD 120K-200K; Principal 15+ years: SGD 200K-300K+.
Southeast Asia
Thailand
Vietnam
Philippines
East Asia
Japan
South Korea
Taiwan
Key Insights on Asian Market Positioning
Talent Quality: India and Singapore produce world-class data scientists competitive globally. Quality talent is no longer concentrated in Western markets.
Wage Arbitrage Narrowing: While significant differentials remain, the gap is narrowing as local companies and global enterprises invest in Asia. Entry-level talent increasingly earns comparable rates across geographies.
Remote Work Disruption: Remote-first companies disrupted location-based pay scales. Talented Asian data scientists now earn 50-100% premiums over local rates when working for US/European companies remotely.
Career Acceleration Opportunity: Steep learning curve and rapid technology evolution in Asia create accelerated career progression. An engineer advancing through multiple roles in 8-10 years might progress to senior/principal levels, significantly multiplying lifetime earnings potential.
Geographic Arbitrage Strategy: Many successful Asian professionals follow this trajectory: (1) Start at local company (build fundamentals), (2) Transition to multinational offshore center (10-20% premium), (3) Move to remote work for US/European companies (50-100% premium), (4) Eventually relocate or maintain remote arrangement at maximum compensation.
Strategic Recommendations & Conclusion
For Aspiring Data Scientists
For Organizations Hiring Data Scientists
Future Trajectory (2026-2027)
Several trends will accelerate:
Generative AI Integration: AI-assisted analytics will become standard. Data scientists using these tools effectively will dramatically outpace those ignoring them.
Specialization Deepens: Roles like NLP Engineer, Computer Vision Specialist, and MLOps Engineer will become primary career paths rather than specializations of "data scientist."
Responsible AI Becomes Non-Negotiable: As regulatory scrutiny increases (EU AI Act, US executive orders), responsible AI expertise will command premium compensation.
Data Democratization: Low-code analytics platforms will commoditize basic analysis; value will shift to strategic insights and complex problems.
Domain Expertise Premium: Data scientists combining deep domain knowledge (healthcare, finance, supply chain) with analytical skills will be highly valued.
Governance & Compliance: Organizations prioritizing data governance, lineage tracking, and compliance will outcompete those ignoring these concerns.
Final Thoughts
Data science has matured from "sexy job" to essential organizational function. The field offers exceptional career trajectory, competitive compensation globally, and meaningful work solving complex problems. Success requires continuous learning, deep technical execution, strategic thinking, and adaptability.
The professionals who thrive combine three capabilities: (1) strong technical execution—building models that work reliably; (2) strategic thinking—understanding how analytics drive business decisions; (3) communication skills—translating complexity into clarity.
Asia's data science ecosystem is rapidly maturing, offering both significant opportunities for talent development and competitive advantages for organizations building distributed teams. Geographic arbitrage opportunities remain significant for ambitious professionals willing to develop expertise and take calculated career steps.
This roadmap provides the foundational structure; individual choices—specialization, geographic strategy, company selection, continuous learning—determine personal trajectory within this dynamic and rewarding field.